Refactoring TEZip: Integrating Python-Based Predictive Compression into an HPC C++/LibTorch Environment (FY2025)
TEZip is a framework for compressing time-evolving image data using predictive deep neural networks. Until now, TEZip primarily relied on Python libraries (TensorFlow or PyTorch). This work presents a new TEZip pipeline built with C++/LibTorch for improved speed and High performance Computing (HPC) compatibility. Across multiple datasets, our C++/LibTorch implementation preserves accuracy and compression ratios while speedup the time 1.1–4x (training), 11-13.7x (compression), and 3.7-5x (decompression), primarily by eliminating Python overhead and leveraging optimized C++ kernels on modern CPU/GPU clusters.

An Optimization Technique for Hiding Communication Costs in 3D Parallel Training of Deep Learning (FY2025)
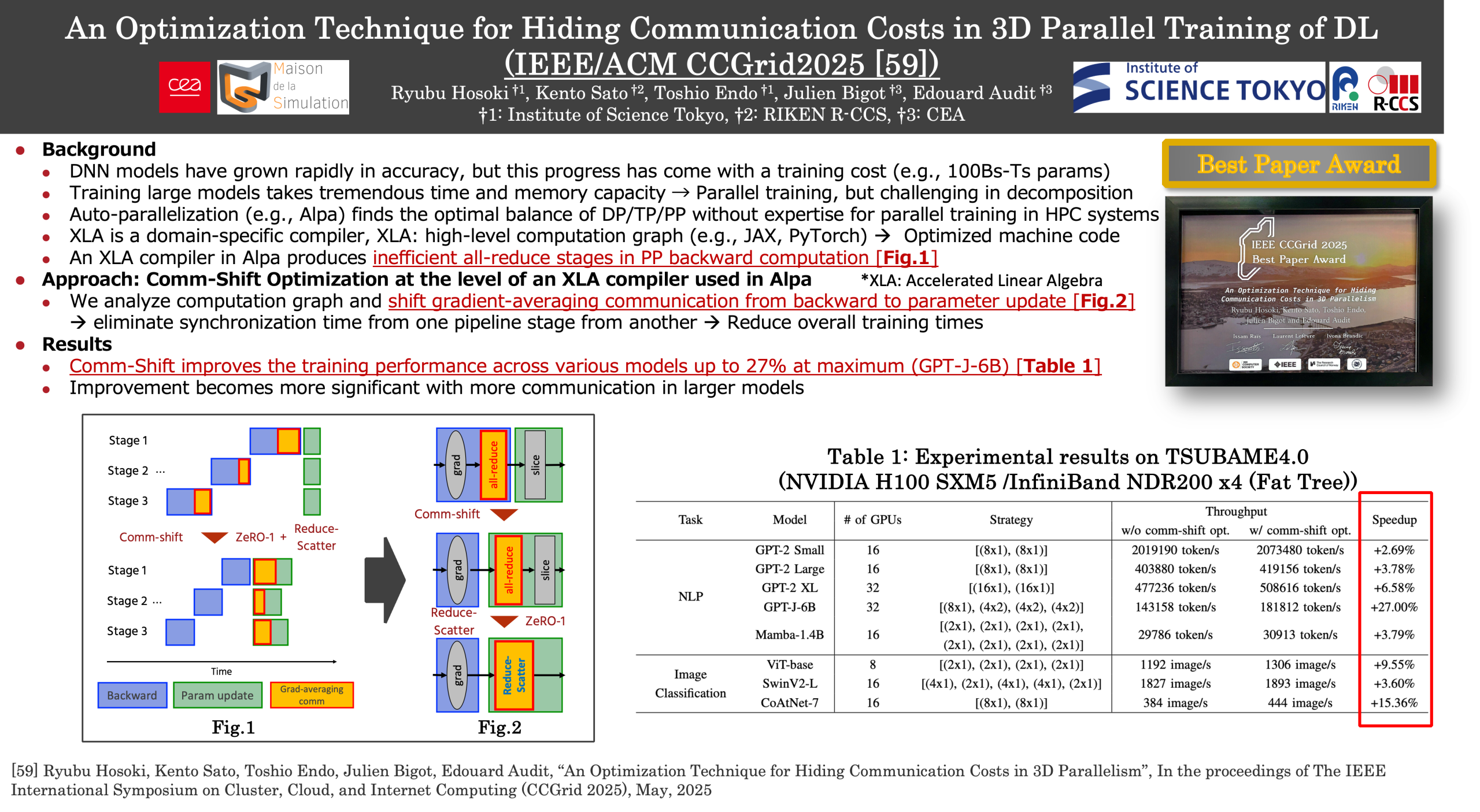
In large-scale model training, distributing the work-load is essential to address memory usage and computation time constraints. 3D parallelism, which combines data parallelism, tensor parallelism, and pipeline parallelism, has emerged as a state-of-the-art method for distributed training. However, exploring optimal parallel strategies and modifying code places a significant burden on users. While some machine learning compilers support automatic parallelization, they are generally limited to SPMD parallelism and do not support the automation of 3D parallelism, including MPMD parallelism for pipeline parallelism. This study identifies key issues in implementing 3D parallelism with the XLA machine learning compiler, particularly communication delays caused by the limitations of sharding notation in XLA’s intermediate representation. To address this, we propose a comm-shift optimization, which relocates specific communication instructions to different computation phases, reducing the impact of communication waiting times. This optimization reduces training time, achieving up to a 27% throughput improvement in GPT-J training.
Distributed Order Recording Techniques for Efficient Record-and-Replay of Multi-threaded Programs (FY2024)
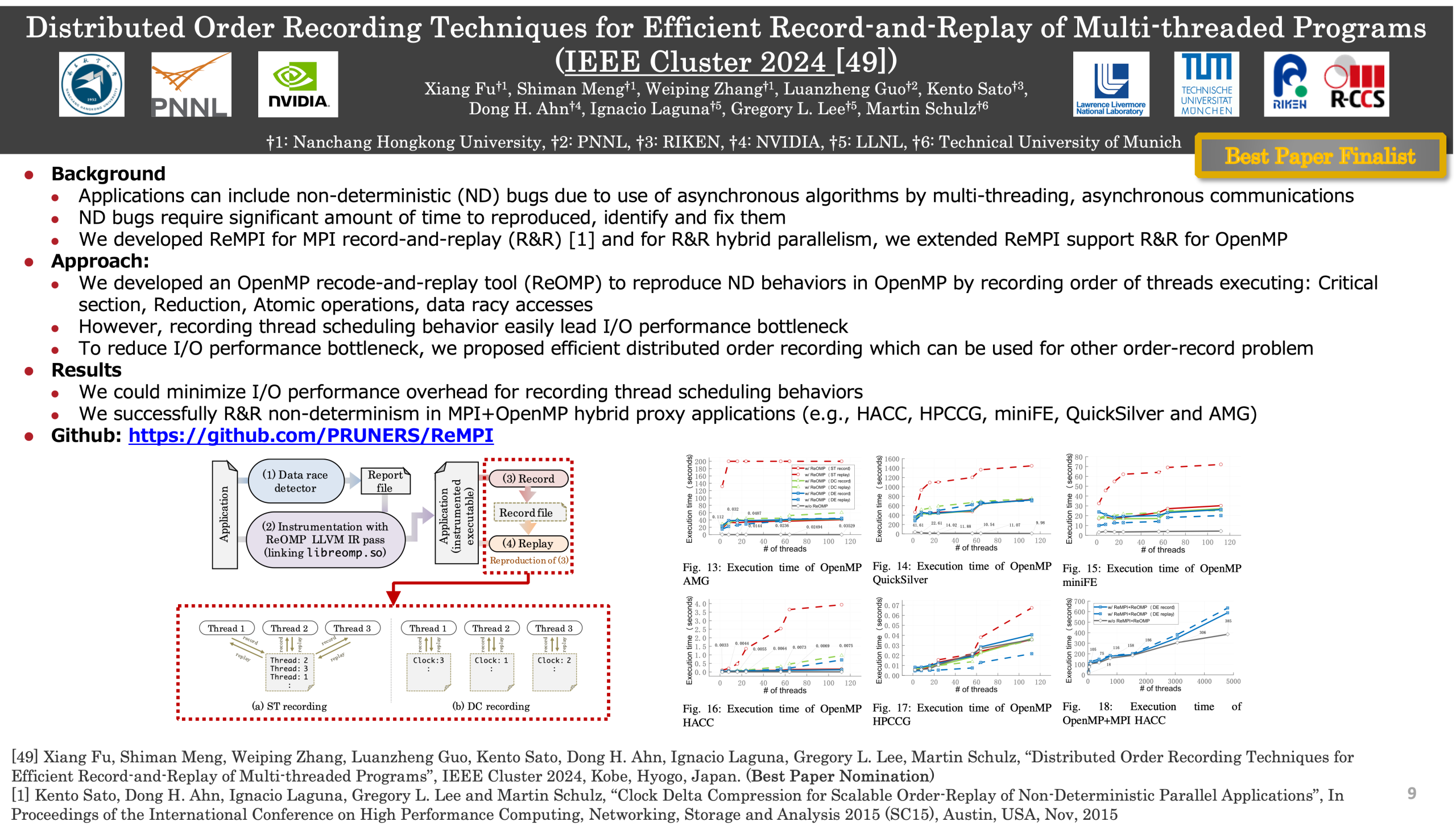
After all these years and all these other shared memory programming frameworks, OpenMP is still the most popular one. However, its greater levels of non-deterministic execution makes debugging and testing more challenging. The ability to record and deterministically replay the program execution is key to address this challenge. However, scalably replaying OpenMP programs is still an unresolved problem. In this paper, we propose two novel techniques that use Distributed Clock (DC) and Distributed Epoch (DE) recording schemes to eliminate excessive thread synchronization for OpenMP record and replay. Our evaluation on representative HPC applications with ReOMP, which we used to realize DC and DE recording, shows that our approach is 2-5x more efficient than traditional approaches that synchronize on every shared-memory access. Furthermore, we demonstrate that our approach can be easily combined with MPI-level replay tools to replay non-trivial MPI+OpenMP applications. We achieve this by integrating ReOMP into ReMPI, an existing scalable MPI record-and-replay tool, with only a small MPI-scale-independent runtime overhead.
Operational Experience with Incentive-Based Power Efficiency Mechanisms on the Fugaku Supercomputer (FY2024)
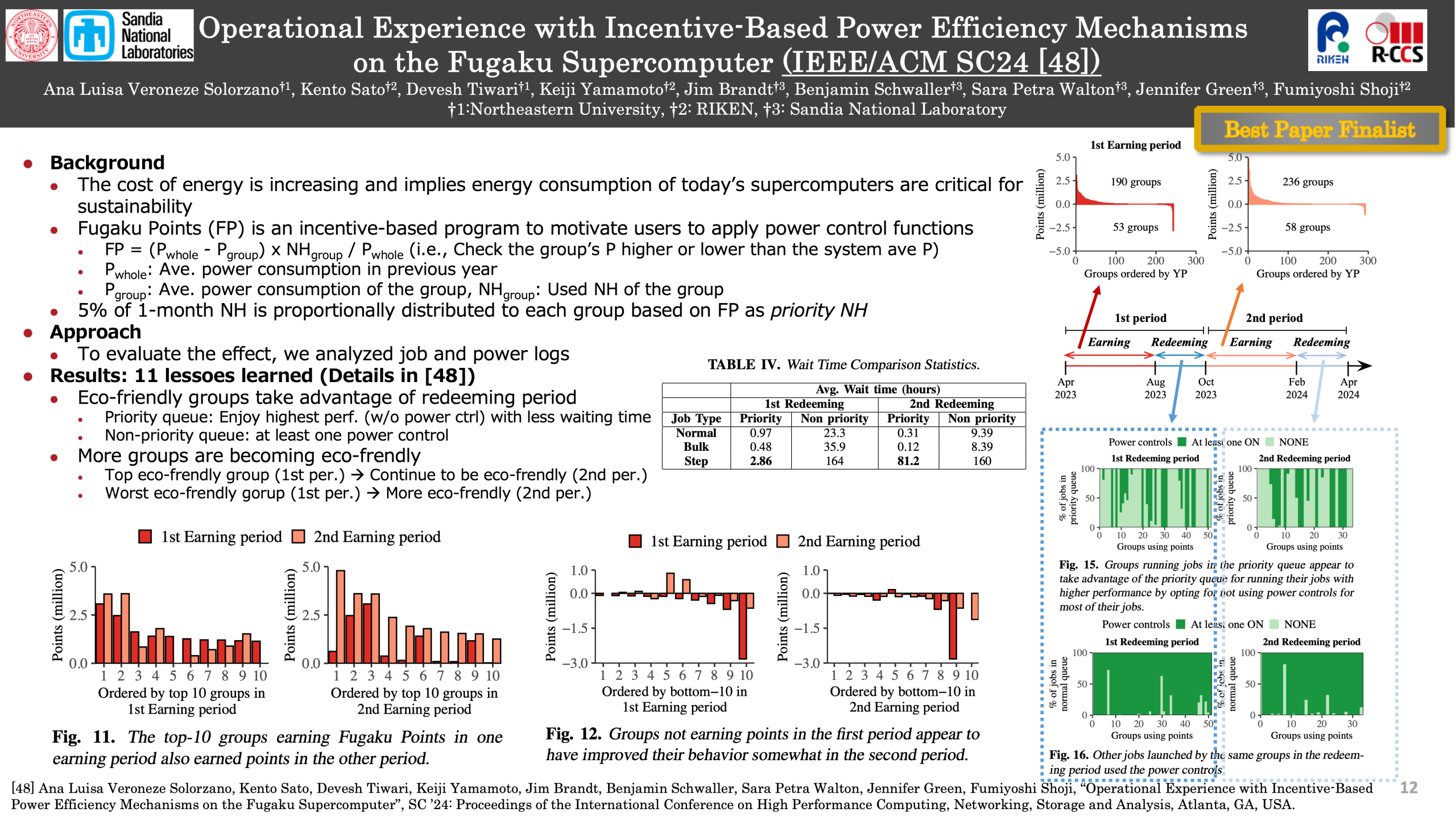
In this paper, we present our operational experience with deploying an incentive-based power control program for jobs submitted on a top-500 supercomputer. We present one full year of the program in practice over two periods. We show that such a program encourages sustained power awareness among users, provided there are mechanisms to support their power-saving efforts. Besides, we discuss new operational opportunities and challenges created by the incentive-based program.
AutoCheck: Automatically Identifying Variables for Checkpointing by Data Dependency Analysis (FY2024)
Checkpoint/Restart (C/R) has been widely deployed in numerous HPC systems, Clouds, and industrial data centers, which are typically operated by system engineers. Nevertheless, there is no existing approach that helps system engineers without domain expertise, and domain scientists without system fault tolerance knowledge identify those critical variables accounted for correct application execution restoration in a failure for C/R. To address this problem, we propose an analytical model and a tool (AutoCheck) that can automatically identify critical variables to checkpoint for C/R. AutoCheck relies on first, analytically tracking and optimizing data dependency between variables and other application execution state, and second, a set of heuristics that identify critical variables for checkpointing from the refined data dependency graph (DDG). AutoCheck allows programmers to pinpoint critical variables to checkpoint quickly within a few minutes. We evaluate AutoCheck on 14 representative HPC benchmarks, demonstrating that AutoCheck can efficiently identify correct critical variables to checkpoint.

A64FX – Your Compiler You Must Decide! (FY2021)
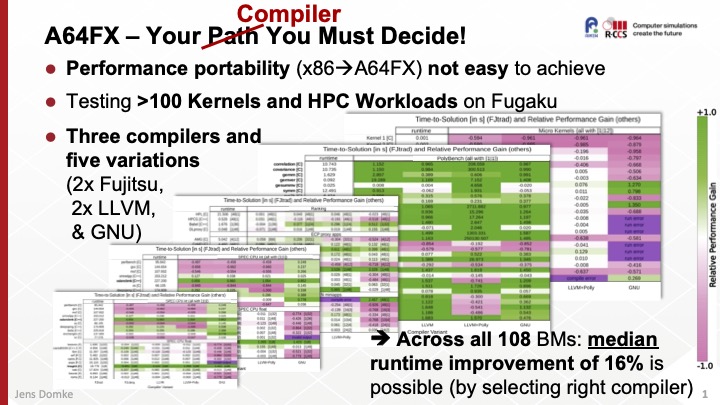
The current number one of the TOP500 list, Supercomputer Fugaku, has demonstrated that CPU-only HPC systems aren’t dead and CPUs can be used for more than just being the host controller for a discrete accelerators. While the specifications of the chip and overall system architecture, and benchmarks submitted to various lists, like TOP500 and Green500, etc., are clearly highlighting the potential, the proliferation of Arm into the HPC business is rather recent and hence the software stack might not be fully matured and tuned, yet. We test three state-of-the-art compiler suite against a broad set of benchmarks. Our measurements show that orders of magnitudes in performance can be gained by deviating from the recommended usage model (i.e., 4 MPI ranks with 12 OpenMP threads each) and recommended compiler for the A64FX compute nodes. Furthermore, our work shows that there is currently no “silver bullet” compiler for A64FX, and hence the operations team of Fugaku added an official LLVM installation based on our findings.
Related Publication
- J. Domke, “A64FX – Your Compiler You Must Decide!,” in Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), EAHPC Workshop, (Portland, Oregon, USA), IEEE Computer Society, Sept. 2021.
Matrix Engines for High Performance Computing: A Paragon of Performance or Grasping at Straws? (FY2021)
Matrix engines or units, in different forms and affinities, are becoming a reality in modern processors; CPUs and otherwise. The current and dominant algorithmic approach to Deep Learning merits the commercial investments in these units, and deduced from the No. 1 benchmark in supercomputing, namely High Performance Linpack, one would expect an awakened enthusiasm by the HPC community, too. Hence, our goal was to identify the practical added benefits for HPC and machine learning applications by having access to matrix engines. For this purpose, we performed an in-depth survey of software stacks, proxy applications and benchmarks, and historical batch job records. We provided a cost-benefit analysis of matrix engines, both asymptotically and in conjunction with
state-of-the-art processors. While our empirical data will temper the enthusiasm, we also outline opportunities to “misuse” these dense matrix-multiplication engines if they come for free in future CPU or GPU architectures.
Related Publication
- J. Domke, E. Vatai, A. Drozd, P. Chen, Y. Oyama, L. Zhang, S. Salaria, D. Mukunoki, A. Podobas, M. Wahib, S. Matsuoka, “Matrix Engines for High Performance Computing: A Paragon of Performance or Grasping at Straws?,” in Proceedings of the 35th IEEE International Parallel & Distributed Processing Symposium (IPDPS), (Portland, Oregon, USA), IEEE Computer Society, May 2021.
Compression of Time Evolutionary Image Data through Predictive Deep Neural Networks (FY2021)
Recent advances in Deep Neural Networks (DNNs) have demonstrated a promising potential in predicting the temporal and spatial proximity of time evolutionary data. In this paper, we have developed an effective (de)compression framework called TEZIP that can support dynamic lossy and lossless compression of time evolutionary image frames with high compression ratio and speed. TEZIP first trains a Recurrent Neural Network called PredNet to predict future image frames based on base frames, and then derives the resulting differences between the predicted frames and the actual frames as more compressible delta frames. Next we equip TEZIP with techniques that can exploit spatial locality for the encoding of delta frames and apply lossless compressors on the resulting frames. Furthermore, we introduce window-based prediction algorithms and dynamically pinpoint the trade-off between the window size and the relative errors of predicted frames. Finally, we have conducted an extensive set of tests to evaluate TEZIP. Our experimental results show that, in terms of compression ratio, TEZIP outperforms existing lossless compressors such as x265 by up to 3.2x and lossy compressors such as SZ by up to 3.3x.
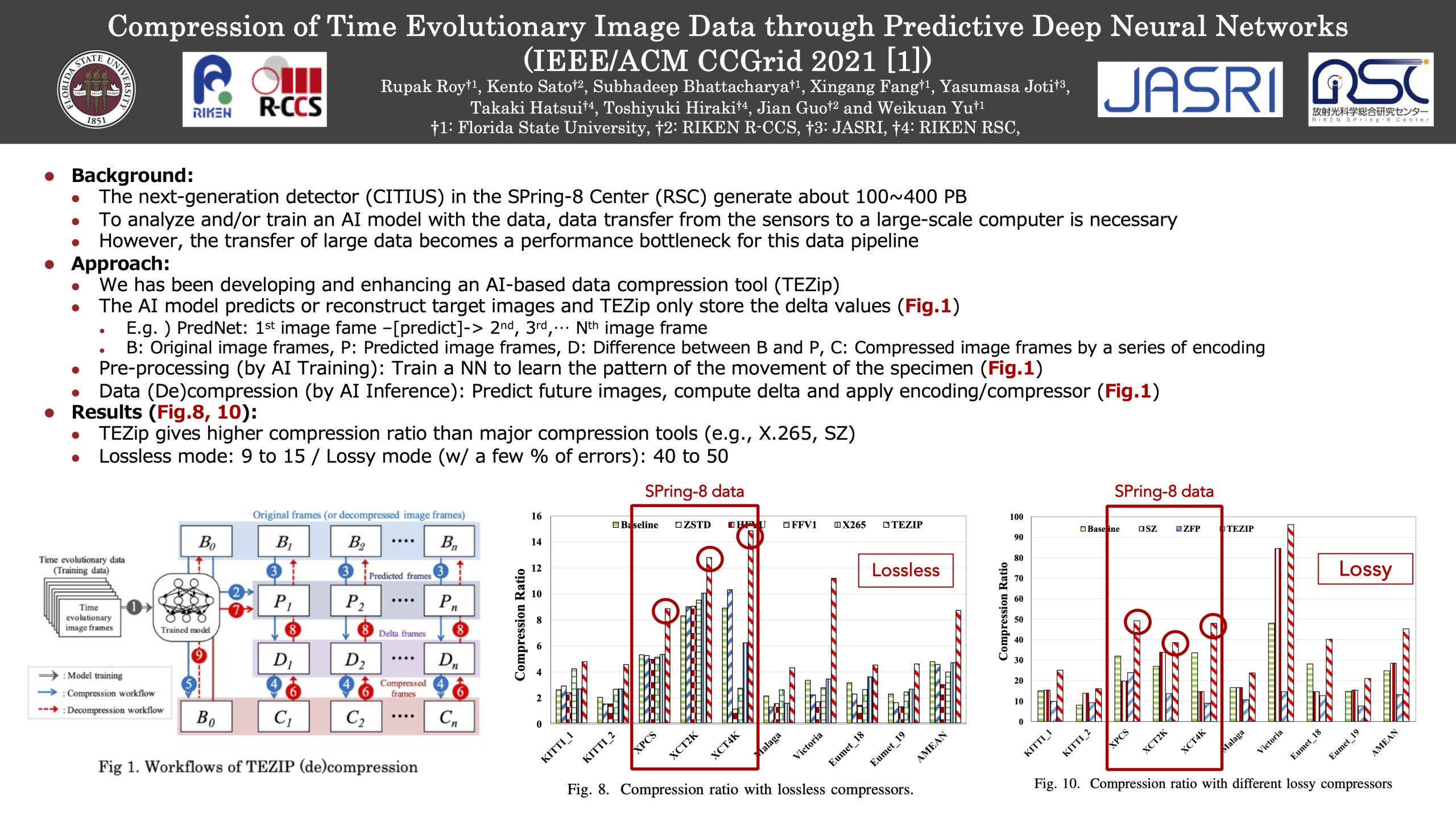
Publications:
- Rupak Roy, Kento Sato, Subhadeep Bhattacharya, Xingang Fang, Yasumasa Joti, Takaki Hatsui, Toshiyuki Hiraki, Jian Guo and Weikuan Yu, “Compression of Time Evolutionary Image Data through Predictive Deep Neural Networks”, In the proceedings of the 21 IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGrid 2021), May, 2021
- Rupak Roy, Kento Sato, Jian Guo, Jens Domke and Weikuan Yu, “Improving Data Compression with Deep Predictive Neural Network for Time Evolutional Data”, In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis 2019 (SC19), Regular Poster, Denver, USA, Nov, 2019.
Optimizing Asynchronous Multi-Level Checkpoint/Restart Configurations with Machine Learning (FY2020)
With the emergence of versatile storage systems, multi-level checkpointing (MLC) has become a common approach to gain efficiency. However, multi-level checkpoint/restart can cause enormous I/O traffic on HPC systems. To use multilevel checkpointing efficiently, it is important to optimize check-point/restart configurations. Current approaches, namely modeling and simulation, are either inaccurate or slow in determining the optimal configuration for a large scale system. In this paper, we show that machine learning models can be used in combination with accurate simulation to determine the optimal checkpoint configurations. We also demonstrate that more advanced techniques such as neural networks can further improve the performance in optimizing checkpoint configurations.
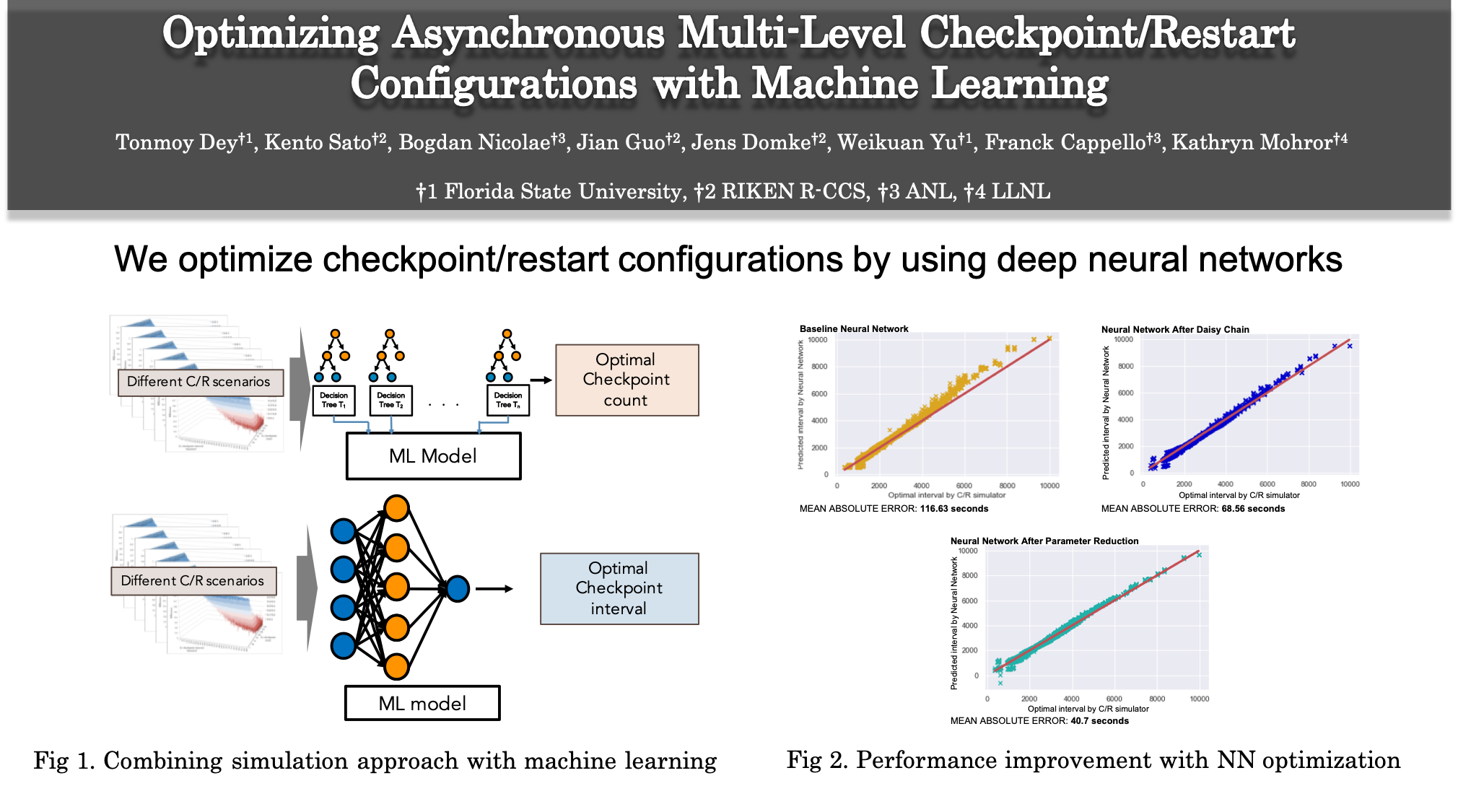
Publications:
- Tonmoy Dey, Kento Sato, Bogdan Nicolae, Jian Guo, Jens Domke, Weikuan Yu, Franck Cappello, and Kathryn Mohror. “Optimizing Asynchronous Multi-Level Checkpoint/Restart Configurations with Machine Learning.” The IEEE International Workshop on High-Performance Storage, May, 2020
- Tonmoy Dey, Kento Sato, Jian Guo, Bogdan Nicolae, Jens Domke, Weikuan Yu, Franck Cappello and Kathryn Mohror, “Optimizing Asynchronous Multi-level Checkpoint/Restart Configurations with Machine Learning”, In Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis 2019 (SC19), Regular Poster, Denver, USA, Nov, 2019.